Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi Editorial, Int J Glob Health Vol: 5 Issue: 1
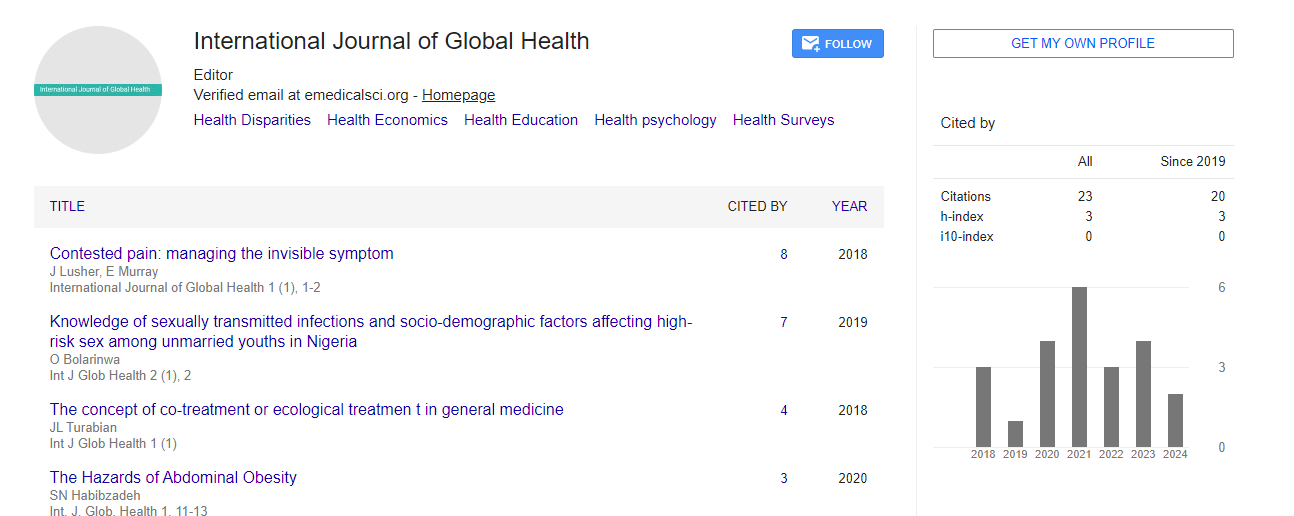
A Multicenter Study to Evaluate the Disease Burden and Health Economics
Weifang Liu*
Institute of EcoHealth, Cheeloo College of Medicine, Shandong University, Jinan, China
*Corresponding Author:
Weifang Liu
Institute of EcoHealth, Cheeloo College of Medicine, Shandong University, Jinan, China
E-mail:weifangl@gmail.com
Received: 02 January, 2022, Manuscript No. IJGH-22-57275;
Editor assigned: 04 January, 2022, PreQC No. IJGH-22-57275 (PQ);
Reviewed: 15 January, 2022, QC No IJGH-22-57275;
Revised: 23 January, 2022, Manuscript No. IJGH-22-57275 (R);
Published: 30 January, 2022, DOI: 10.4172/Ijgh.1000154
Citation: Liu W (2022) A Multicenter Study to Evaluate the Disease Burden and Health Economics. Int J Glob Health 5:1.
Keywords: Health Education, Health psychology, Health Surveys
Editorial Note
The primary item of statistical analysis is to find out whether the impact produced via manner of a compound under have examine is actual and isn't always due to risk. Consequently, the evaluation usually attaches a test of statistical importance. First step on this type of test is to state the null speculation. In null speculation, we make assumption that there exist no variations among the two groups. Alternative hypothesis (studies speculation) states that there is a difference between organizations [1]. For example, a brand new drug ‘A’ is claimed to have analgesic hobby and we want to test it with the placebo. On this have examine, the null hypothesis might be drug A is not better than the placebo. Opportunity speculation could be ‘there may be a distinction among new drug ‘A’ and placebo. Whilst the null speculation is common, the difference among the two corporations isn't widespread. It manner, each samples had been drawn from single populace, and the difference obtained amongst two companies changed into due to danger. If opportunity hypothesis is proved i.e., null hypothesis is rejected, then the distinction amongst two companies is statistically. A difference among drug ‘A’ and placebo organization, which may have arisen by way of manner of threat is less than five% of the cases, this is much less than 1 in 20 times is taken into consideration as statistically incredible. In any experimental system, there can be opportunity of going on mistakes that is also known as α blunder. It’s far the opportunity of finding a distinction; whilst no such difference simply exists, which results inside the recognition of an inactive compound as an energetic compound [2]. Such an errors which is not unusual can be tolerated because in subsequent trials, the compound will reveal itself as inactive and hence ultimately rejected. As an example, we proved in our trial that new drug ‘A’ has an analgesic movement and everyday as an analgesic.
Analgesic Motion
If we commit kind I mistakes in this experiment, then next trial in this compound will automatically reject our claim that drug ‘A’ is having analgesic motion and afterward drug ‘A’ can be thrown out of marketplace. Type I mistakes is truly fixed earlier via preference of the quantity of significance employed in test. It could be stated that kind I blunders may be made small through way of converting the extent of importance and by using developing the dimensions of pattern [3] that is also known as β mistakes. Its miles the threat of disability to come across the difference at the same time as it actually exists consequently ensuing in the rejection a lively compound as an inactive. This mistake is more essential than type I blunders because as soon as we labeled the compound as inactive; there may be possibility that no one will attempt it once more [4]. As a result, an energetic compound may be misplaced. This form of errors may be minimized via taking huge sample and through using enough dose of the compound below trial [5]. As an example, we claim that drug ‘A’ isn't always having analgesic pastime after suitable trial. therefore, drug ‘A’ will no longer be attempted with the resource of some other researcher for its analgesic interest and as a result drug ‘A’, in spite of having analgesic interest, may be out of place simply because of our kind II mistakes. Consequently, researcher needs to be very careful on the equal time as reporting kind II errors.
If the opportunity (P) of an event or final results is immoderate, we are pronouncing it is not rare or no longer unusual. However, if the P is low, we are saying it's far uncommon or uncommon. In biostatistics, an extraordinary event or final results is called full-size, while a non-uncommon event is called non-large. The ‘P’ price at which we regard an occasion or outcomes as sufficient to be appeared as big is called the importance level. In clinical research, most typically P fee a whole lot much less than 0.05 or 5% is taken into consideration as big stage. But, on justifiable grounds, we can also undertake a distinct well known like P<0.01 or 1%. Every time possible, it's far higher to give real P values instead of P<0.05. Even if we have found the true value or population value from sample, we cannot be confident as we are dealing with a part of population only howsoever big the sample may be [6]. We would be wrong in 5% cases only if we place the population value within 95% confidence limits. Significant or insignificant indicates whether a value is likely or unlikely to occur by chance. ‘P’ indicates probability of relative frequency of occurrence of the difference by chance.
Sometimes, when we analyse the data, one value is very extreme from the others. Such value is referred as outliers. This could be due to two reasons. Firstly, the value obtained may be due to chance; in that case, we should keep that value in final analysis as the value is from the same distribution. Secondly, it may be due to mistake. Causes may be listed as typographical or measurement errors [7]. In such cases, these values should be deleted, to avoid invalid results. When comparing two groups of continuous data, the null hypothesis is that there is no real difference between the groups (A and B). The alternative hypothesis is that there is a real difference between the groups [8]. This difference could be in either direction e.g. A>B or AB and while an incredible floor considers only one opportunity, the check is referred to as one-tailed test. Every time we bear in mind both the possibilities, the take a look at of importance is referred to as a tailed check. As an instance, while we remember that English boys are taller than Indian boys, the quit end result will lie at one surrender this is one tail distribution, therefore one tail take a look at is used [9]. Whilst we are not certainly sure of the course of distinction, this is conventional; its miles continually better to apply two-tailed check. As an instance, a latest drug ‘X’ is meant to have an antihypertensive pastime, and we need to evaluate it with atenolol. In this situation, as we don’t realize actual direction of impact of drug ‘X’, so one have to opt for -tailed take a look at [10]. Even as you need to recognize the movement of unique drug is different from that of a few different, however the direction is not particular, constantly use -tailed test. At gift, maximum of the journals use side P values as a popular norm in biomedical research.
References
- Curran ED, Benos DJ (2004) Guidelines for reporting statistics in journals published by the American Physiological Society. Am J Physiol Regul Integr Comp Physiol 287: 247-249. [Crossref], [Google Scholar], [Indexed]
- Nanivadekar AS, Kannappan AR (1990) Statistics for clinicians. Nominal data (I). J Assoc Physicians India 38: 931-935. [Crossref], [Google Scholar], [Indexed]
- Matthews VL (1967) Community medicine â?? A commentary on the discussion. Can Med Assoc J 97: 730-732. [Crossref], [Google Scholar], [Indexed]
- Nanivadekar AS, Kannappan AR (1991) Statistics for clinicians. Interval data (I). J Assoc Physicians India 39: 403-407. [Crossref], [Google Scholar], [Indexed]
- Thakur HP, Pandit DD, Subramanian P (2001) History of preventive and social medicine in India. J Postgrad Med 47: 283-285. [Crossref], [Google Scholar], [Indexed]
- Ludbrook J (2008) The presentation of statistics in Clinical and Experimental Pharmacology and Physiology. Clin Exp Pharmacol Physiol 35: 1271-1274. [Crossref], [Google Scholar], [Indexed]
- Nanivadekar AS, Kannappan AR (1990) Statistics for clinicians. Introduction. J Assoc Physicians India 38: 853-856. [Crossref], [Google Scholar], [Indexed]
- Bland JM, Altman DG (1996) Transforming data. Br Med J 312: 770. [Crossref], [Google Scholar]
- Ludbrook J (2008) Statistics in Biomedical Laboratory and Clinical Science: Applications, Issues and Pitfalls. Med Princ Pract 17: 1-13. [Crossref], [Google Scholar], [Indexed]
- Lang T (2004) Twenty statistical errors even you can find in biomedical research article. Croat Med J 45: 361-370. [Crossref], [Google Scholar], [Indexed]