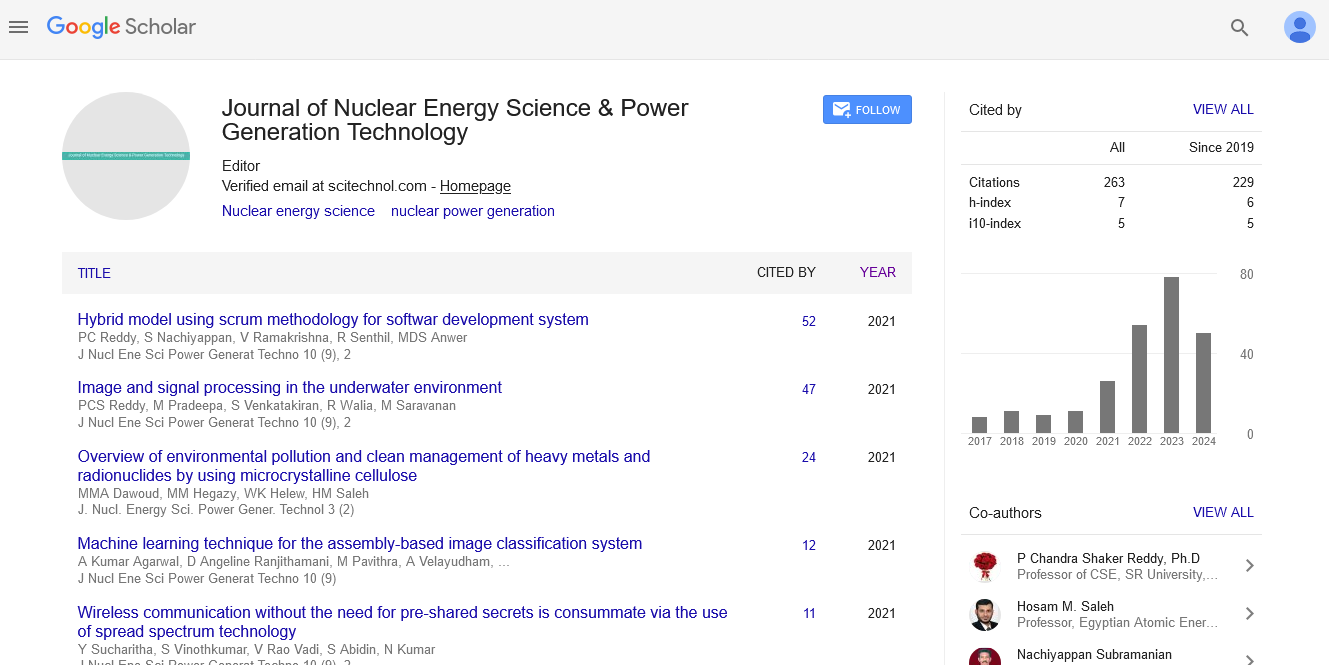
Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi Research Article, J Nucl Ene Sci Power Generat Technol Vol: 10 Issue: 9
Some Enhancements in the Choice of Functionalities for Data Mining and Their Application in Opinion Mining
Brijendra Gupta1*, Girish kulkarni2, A Rajesh Kumar3, VS Padmini4, SM Uma5 and Devika Rani Roy6
1Department of IT, Siddhant College of Engineering, Pune, India
2Department of Computer Science and Engineering, BV Raju Institute of Technology, Narsapur, Telangana, India
3The Karur Polytechnic College, Karur, Tamilnadu, India
4Department of Computer Science and Engineering, Gurunanak Dev Engineering College, Bidar, India
5Department of Computer Science and Engineering, Kings College of Engineering, Punalkulam, Thanjavur, India
6KC College of Engineering and Management Studies and Research Mithbunder Rd, Maharashtra, India
*Corresponding Author:Brijendra Gupta
HOD IT Department, Associate Professor
Siddhant College of Engineering, Pune, India,
E-mail: gupbrij@rediffmail.com
Received: August 31, 2021 Accepted : September 15, 2021 Published : September 22, 2021
Citation: Gupta B, kulkarni G, Kumar RA, Padmini VS, Uma SM, et al. (2021) Some Enhancements in the Choice of Functionalities for Data Mining and their Application in Opinion Mining. J Nucl Ene Sci Power Generat Techno 10:9.
Abstract
Digital marketing is playing an increasingly important role in e-commerce, particularly in terms of sharing meaningful information about a product or service. Information extraction has emerged as the most important technique in digital marketing. The method of recommender systems in social sites while looking at the various types of argumentative documents, as well as the difficulties connected with a machine translation from social media, are addressed in this article. Using an image recognition tool, a K-means clustering algorithm has been used to a sample Twitter database to aggregate various attitudes in relationship with different product characteristics. The technique has been tested and described with the aid of the tool. Computing methods Cluster analysis Topics in Computer Science
Keywords: K-Means; Sentiment Analysis; Analytics; Compatibility
Introduction
Social media monitoring and analysis
The primary goal of the social mainstream press is to maintain a relationship through all online communications such as interactions, sharing of personal views, and receiving necessary information. The primary reason for selecting Social Media Analytics (SMA) is to showcase the goods or services being promoted [1].
•Social platforms have surpassed all other online activities and have become a daily pastime for adults.
•Provides a simple method of grouping consumers via the use of the internet.
•Context of providing about either the Product/Service is simple and quick to do.
All duplicates of this work, whether digital or printed, for individual or classroom use, are permitted without charge, assuming that the reproductions are not produced or disseminated for commercial gain or benefit and that the duplicates carry this declaration and the whole attribution on the very first page. It is necessary to respect the intellectual property rights of those who have contributed to this work. It is permissible to abstract while receiving credit. Any photocopy or reproduction, to put on servers, or to disseminate to mailing lists without previously expressed consent and/or payment is required. Obtain permission from the person you are requesting authorization from
Facilitates the collecting and evaluating comments on a specific Product/Service by providing a simple interface.
Because although Social Media Analytics (SMA) can assist in determining the needs and sense of achievement of users, it is extremely important to obtain accurate or valuable information again from comment sections or likes that are gained on social networking sites. As a result, we must go through a special protocol in process of extracting the appropriate information from multiple information. The Social Networking Tools aid in the collection and interpretation of textual material to make it more structured. The method of "recommender systems" is one of the most important in the field of Social Networking Sites. An "assessment" is a point of view, attitude, or assessment of a thing expressed by a person or organization about that item. Opinion Mining (OM) is a research field that focuses on the collection of views or sentiments from data utilizing. It is all about discovering what individuals believe and how they act. OM must take into consideration the amount of impact that each one point of view has. This may be influenced by a variety of reasons, such as faith in the product, company, or individual.
Organization responsible: It is analogous to a group of individuals who have similar views and who put their faith in the viewpoints of the other members of the team.
Credibility: If your suggestion is similar to whatever the overwhelming of others believes, then you are regarded as experienced and then have a high level of renowned trust.
Information Extraction Via Social Media is Becoming More Popular
A significant amount of opinionated material may be found on every website on the internet; the typical individual comment will have trouble selecting relevant websites and absorbing the opinions and insights included within them [2]. Figure 1 depicts the overall picture of machine translation on social media platforms. Perhaps the views are derived through IR (predictive analytics) operations that gather relevant data from communication channels and from responses to surveys, which are then evaluated for mining. Because the views are combined with a variety of various emotions. When it comes to segmentation, there is a method known as sentiment categorization that is concerned with the segmentation of sentences, documents, and features based on the supports of multiple languages by users, which are either favorable or unfavorable. It is necessary to determine if each phrase conveyed a favorable, unfavorable, or neutral view at this level to proceed.

Figure 1: OM architecture.
For example, Australia has won the 2015 ICC Cricket World Cup.
Document phase: The objective at this level is to categorize the whole viewpoint expressed in a report as either favorable or unfavorable.
For example, a product reviews.
Feature level: Rather than focusing just on language terms, consider the opinions and grammatical relationships between them. It is predicated on the notion that thought is composed of three components: a favorable emotion, an unfavorable attitude, and a recipient of the viewpoint.
“she is overweight,” says direct opinion.
In comparison to running, walking is preferable. Sentence with a comparative structure.
Viewpoint aggregation is the process of bringing together views from a multitude of different, such as blogging, newsgroups, and professional view websites. Data collected from various levels, including the level of the sentence as well as the opinion words, must be included in the system. It is necessary to combine the viewpoint data further via clustering and processing to determine the sentiment, which may be favorable or unfavorable in certain circumstances, or neutral in others. Fake comments, erroneous critical perceptions, and comments with an elevated density of specific phrases fall under the category of Opinion Spam, and identifying and removing spam personal views is one of the most difficult problems faced by information extraction researchers. When doing Opinion Retrieval, it is necessary to obtain documents and rank them according to how people feel about a certain subject. To be relevant, the material must be related to the query subject and should provide views on the issue. To evaluate the effectiveness of Viewpoint Reactivation, a communication and information pertinent questions on a subject, known as a survey, was given to 200 students over email. Of something like the 200 students, 57 replied to the email and expressed their opinions by analyzing the responses. The subject of discussion is the degree of happiness and views expressed by Social media users when using the service. The vast proportion of students had been using Twitter for more than a year, and even the majority of them would be between the ages of 21 and 23. Table 1 shows the students' perceptions of the characteristics of Twitter as expressed via their comments.
| Question | Good | Bad | Very bad | Very satisfied |
|---|---|---|---|---|
| Business | 48 | 6 | 3 | 0 |
| Education | 35 | 16 | 2 | 4 |
| User friendly | 19 | 23 | 10 | 5 |
| Logo | 37 | 5 | 5 | 10 |
| Business services | 24 | 8 | 8 | 17 |
| Interests | 23 | 9 | 2 | 23 |
| Groups | 15 | 10 | 10 | 22 |
| Adverting | 43 | 4 | 6 | 4 |
| Design | 42 | 7 | 7 | 1 |
| Notifications | 29 | 16 | 3 | 8 |
| Game apps | 28 | 15 | 9 | 5 |
| A/C dress UP | 24 | 16 | 9 | 8 |
| Shopping | 23 | 15 | 14 | 5 |
| Knowledge | 35 | 5 | 5 | 12 |
| Useful | 17 | 20 | 15 | 5 |
Table 1: Opinions of the students about twitter features.
Figures 2 and 3 provide a more comprehensive graph of the data presented previously. Figure 2: When asked about Twitter's functionalities, 52 percent said they were happy with them, 15 percent said they were very comfortable, and 33 percent said they were dissatisfied with several of the aspects. The performance criteria of certain 57 users are shown in the pie chart.

Figure 2: Twitter-user responses and suggestions.

Figure 3: Usability testing levels are shown as a proportion for twitter.
According to the results of the attitude retrieving survey, the views or emotions of the users change depending on the context of the subject. Because we take into account the views of the customers, we may divide the people into three distinct categories.
Users who are (i) Favorable vs users who are (ii) Unfavorable nor (iii) Neutral
In social networking sites, Favorable Users are those who have a favorable view about something like an item or service, Bad Users or who have unfavorable remarks posted about them, and Neutral Customers are anyone who does not respond to any posts or views made on social media.
Managing Information Extraction on Media Platforms is a Difficult Task
It is concerned with just a wealth of knowledge on a user's activity and interests in social networking sites. Information extraction in social networking sites is difficult because of the variety of text kinds and areas, as well as the fact that documents may be in several languages, for example, Greek papers may include phrases through both English and Greek. The Word Embedding between the United Kingdom and the European Union is shown in Table 2 [3].
| What the British say | What the British mean | What others understand |
|---|---|---|
| I hear what you say | I disagree and do not want to discuss it farther |
He accepts my point of view |
| With the greatest respect. |
I think you are an idiot | He is listening to me |
| That's not bad | That's good | That's poor |
| That is very brave proposal | You are insane | He thinks I have courage |
| Quite good | A bit disappointing | Quite good |
| I would suggest | Do it or be prepared to justify yourself |
Think about the idea, but do what you like |
| Oh, incidentally/by the way | The primary purpose of our discussion is. | That is not very important |
| I was a bit disappointed that | I am annoyed that | It doesn’t 't really matter |
| Very interesting | That is clearly nonsense | They are impressed |
| I'll bear it in mind | I've forgotten it already | They will probably do it |
| I'm sure it's my fault | It's your fault | Why do they think it was their fault? |
| You must come for dinner |
It's not an invitation, I'm just being polite |
I will get an invitation soon |
| I almost agree | I don 't agree at all | He's not far from agreement |
| I only have few minor comments |
Please re-write completely |
He has found a few typos |
| Could we consider some other options |
I don't like your idea |
They have not yet decided |
Table 2: The Anglo-European set of data was exposed to a sentimental analysis.
Hopeful, Adverse, and Balanced collections of POS tags are used to examine the differences in the dispersion of POS tags between the three sets. Some point-of-sale tags (POS labels) are significant predictors of psychological (attitude) content. The most difficult issue in opinion mining is determining the emotion including its user and how it changes in the language manifestations of someone's view, which is referred to as "Emotional Assessment." With the use of Emotional Research, you may construct several sub-components that have an impact on the intensity of a feeling [4]. Hopeful, unfavorable, or neutrality polarization may be associated with an emotion. As we mentioned before, various degrees of categorization are used to categorize feelings. Clustering is a technique that separates related items from the rest of the elements in a collection. One of the most difficult issues in the emotional analysis is identifying and categorizing the potential customers. There are many machine learning algorithms available that may be used to categorize audiences that are similar in some way. Now possess k-means clustering, which is one of the more straightforward clustering methods.
Clustering is a term used by social networking sites and their consumer analytics to describe the grouping of individuals who have similar opinions. Data clustering is a technique for dividing large datasets of online users into smaller groups of comparable data that may be analyzed more effectively. The k-means proposed technique is one example of a clustering technique that is used to split datasets into several groups where k is a numeric value. The following is the algorithm for computing k-means:
1.Choose c centroids at random from the list.
2.Determine the distance between each centroid VI and all of the data values XI.
3.Repeat
4.Allocate each performance when compared xi to the center with the shortest distance between them.
5.Compute the new centroids for each new set of data.
6.Computes the number between each new centroid and all of the data points.
7.Till no piece of information was given a new centroid, the process was repeated.
A total of two stages are involved. The first stage is to generate a random number of centers within each grouping; the second step is to calculate the separation across sample points in the information and identify the centroid by allocating the possible explanation to the cluster that is closest to it [5,6]. The Standard Deviation was calculated Criterion Method is used to complete the first and second stages, as well as the Euclidian distance technique k-means is given by the Square Error Threshold, which is determined by relation (1).
F = ∑ ∑ |Q − Ni | → (1)
i=1 peci
Specifically, Q represents the piece of evidence, Ni is the Centroid for Coordination, and F represents the total of squared errors for all elements in the database.
The Euclidian separation is a locus of points in a cluster that is often used to compute the location between them. It is possible to determine the distance of two directions while using the calculation (2).
X = (X1, X2, X3, … . . X��) & Y= (Y1, Y2,Y 3, … . . Yn)

Pseudocode for the k-means clustering approach
Input: n data points di (i=1 to N), number of clusters=k, a database of n pieces of information di (i=1 to N).
Output: N observations grouped into k groups [3].
Methodology
Clustering product features for opinion
Mining by Using Twitter Data
When it comes to influencing users to get interested in a business and its goods, Twitter is an essential instrument. User groups may easily be formed on Twitter, as well as direct communication with the business. To better target its Favorable audience, a company may gather together those who have continuously had a favorable view about its product.
Users on a user's followed list on Twitter can follow many other individuals. On Twitter, a 'Tweet' is a status update that is exchanged with other users and may be used as their status update by the person who shared it. Users with favorable opinions may impact more than ten other users with their tweets, thus it is possible to group favorable and unfavorable users of digital media by applying a simple segmentation procedure.
Weka
In data mining activities, weka is a set of machine learning technologies that may be used to improve accuracy. It is possible to apply the algorithms directly to a dataset or to invoke them from inside your Java code. It includes tools for data pre-processing, classification, regression, clustering, association rules, and visualization, as well as other capabilities. Also, it is an excellent tool for building new machine learning algorithms on large amounts of data [7].
K-means clustering technique for sentiment mining: An application
To demonstrate how the method works, a sample Twitter dataset has been used to demonstrate how the k-means grouping technique can be used to discover various views and sentiments, such as favorable, unfavorable, and neutral, based on the data. It consists of 4612 views on a certain product, of which 1026 are from the Apple dataset, 1230 from the Google dataset, 1257 from the Microsoft dataset, and 1098 from the Twitter dataset [8-16].
Simple k-means is a standard k-means method; k-means will take any dataset with a nominal or mathematical value and cluster it into groups of similar data. Preprocessing divides the text into features, i.e., one word is treated as a single feature; if the word appears in the tweet, the feature value is set to '1'; otherwise, the feature value is set to '0'. A method known as K-means tries to divide the use of words into two types of clusters: those with similar words, and those without similar words. It will generate the cluster after finding the four centroids that are closest to one set of points and farthest from the other. When we choose k=4, it will generate four centroids that are closest to one set of points and farthest from the other. Each tweet can be thought of as a 'Point' in a cluster, with each point varying in distance from each of the centroids. When a tweet (point) is received, it is added to the cluster whose centroid is closest to the tweet. Thus, we will end up with a total of four clusters we will receive four different sentiments for each tweet (point), which are favorable, unfavorable, neutral, and irrelevant.
When we used Weka, we assigned the “Class” attribute with four values: favorable (the most frequently occurring class), unfavorable (the least frequently occurring class), neutral (the most frequently occurring class), and irrelevant (the attribute with no value). We also assigned “Classes to Cluster” to count which class appears the most frequently in the cluster.
In one cluster, for example, if there are three unfavorable points (tweets) and one favorable point (reply), we can label the cluster as "Unfavorable."
With this information, we can figure out what class each cluster represents. Counting the number of points that are in the "Favorable" Cluster gives the result with the number of favorable points equal to 'n'.
Results and Discussion
As previously discussed, Figure 4 depicts the clustering of opinions about different products, with the statistical values depicted in the background. Figure 5 depicts the final results of the clustering of different product sentiments after they have been combined.

Figure 4: Perception on the aggregation of various products.

Figure 5: Products vs. sentiments grouping using a k-means clustering algorithm.
A sample data set is shown in Table 3 with the percentage levels of getting favorable opinions on it. It was discovered and clustered by using the k-means algorithm that 13.5% of them were associated with Apple, 15% with Google, 4% with Microsoft, and 7% with Twitter. Users' favorable opinions and reviews are collected, and a group of users can be identified by using their Twitter handles from the dataset. This allows a company to broaden its service offerings and reach a wider range of potential customers.
| Product | Postitive (Cluster 0) | Negative (Cluster 1) | Neutral (Cluster 2) | Irrelevant (Cluster 3) |
|---|---|---|---|---|
| Apple | 139 | 294 | 478 | 127 |
| 187 | 44 | 549 | 460 | |
| Microsoft | 52 | 66 | 494 | 329 |
| 77 | 99 | 600 | 616 |
Table 3: Target audience opinions on product/service.
Conclusion
The study focuses on the process of opinion mining via the use of text analytics, as well as a short discussion of the difficulties associated with collaborative filtering. A business needs to be aware of its customers' perceptions of its goods and services. The application of emotion analysis may aid in the identification of valuable material in a text. In this case, K-means is used in the test datasets, with the data being divided into various types of clusters, with emotions as a factor taken into account. It has been taught how to conduct a comparative study of various goods and distinct emotions. Last but not least, the cluster of consumers who have a favorable view of the product is taken into consideration, and the k-means classification technique is used. As a result, it provides a straightforward method of directly approaching a favorable audience that may represent the development and quality of a business. This article discusses the mining of user opinions via the analysis of text documents. It is possible to improve the job by concentrating on machine learning such as pictures and videos for machine translation purposes. This gives the impression of originality and commitment.
References
- Weiguo F and Michael GD (2014) Unveiling the power of social media analytics university of michigan ann arbor forthcoming. Commun Acm 57: 74-81
- Neha S, Joshi, Suhasini A, Itkat (2014) A Survey on feature level sentiment analysis. Int J Comput Sci 5: 5422-5425.
- http://www.oxfamblogs.org/fp2p/wp-content/uploads/Anglo- vs-EU.jpg.
- Maynard D, Bontcheva K, Dominic R (2012) Challenges in developing opinion mining tools for social media In: proceedings of the tenth international conference on language resources and Evaluation (LREC 2016). 10th edition of the language resources and evaluation conference. Lang Resour Eval pp: 1142-1148
- Bhatia MPS, Khurana D (2013) Experimental study of data clustering using k-means and modified algorithms. IJDKP pp: 3
- Srihari A, Aditi A, Ananad V (2012) Identifying online opinion leaders using k-means clustering. 2012 12th International Conference On Intelligent Systems Design And Applications, ISDA.
- Deepthi T, Balamurugan K, Uthayakumar M (2021) Simulation and experimental analysis on cast metal runs behaviour rate at different gating models. IJESMS 12: 156-64.
- Devaraj S, Malkapuram R, Singaravel B (2021) Performance analysis of micro textured cutting insert design parameters on machining of Al-MMC in turning process. Int J Lightweight Mater Manuf 4: 210-7
- Garigipati RK, Malkapuram R (2020) Characterization of novel composites from polybenzoxazine and granite powder. SN Applied Sciences 2: 1-9.
- Yarlagaddaa J, Malkapuram R (2020) Influence of carbon nanotubes/graphene nanoparticles on the mechanical and morphological properties of glass woven fabric epoxy composites. INCAS Bull 12: 209-18.
- Rama krishna M, Tej kumar KR, DurgaSukumar G (2018) Antireflection nanocomposite coating on PV panel to improve power at maximum power point. Energy Sources A: Recovery Util Environ Eff 40: 2407-14.
- Yarlagaddaa J, Malkapuram R, Balamurugan K (2021) Machining studies on various Ply orientations of glass fiber composite. In advances in industrial automation and smart manufacturing. pp: 753-769.
- Ezhilarasi TP, Kumar NS, Latchoumi TP, Balayesu N (2021) A secure data sharing using IDSS CP-ABE in cloud storage. In advances in industrial automation and smart manufacturing. pp: 1073-1085.
- Mishra P, Jimmy L, Ogunmola GA, Phu TV, Jayanthiladevi A (2020) Hydroponics cultivation using real time IOT measurement system. J Phys Conf Ser pp:1712-012040
- Sridharan K, Sivakumar P (2018) A systematic review on techniques of feature selection and classification for text mining. Int J Bus Inf Syst 28: 504-518.
- Vemuri RK, Reddy PCS, Kumar BP, Ravi J, Sharma S, et al. (2021) Deep learning based remote sensing technique for environmental parameter retrieval and data fusion from physical models. Arab J Geosci 14: 1-10.