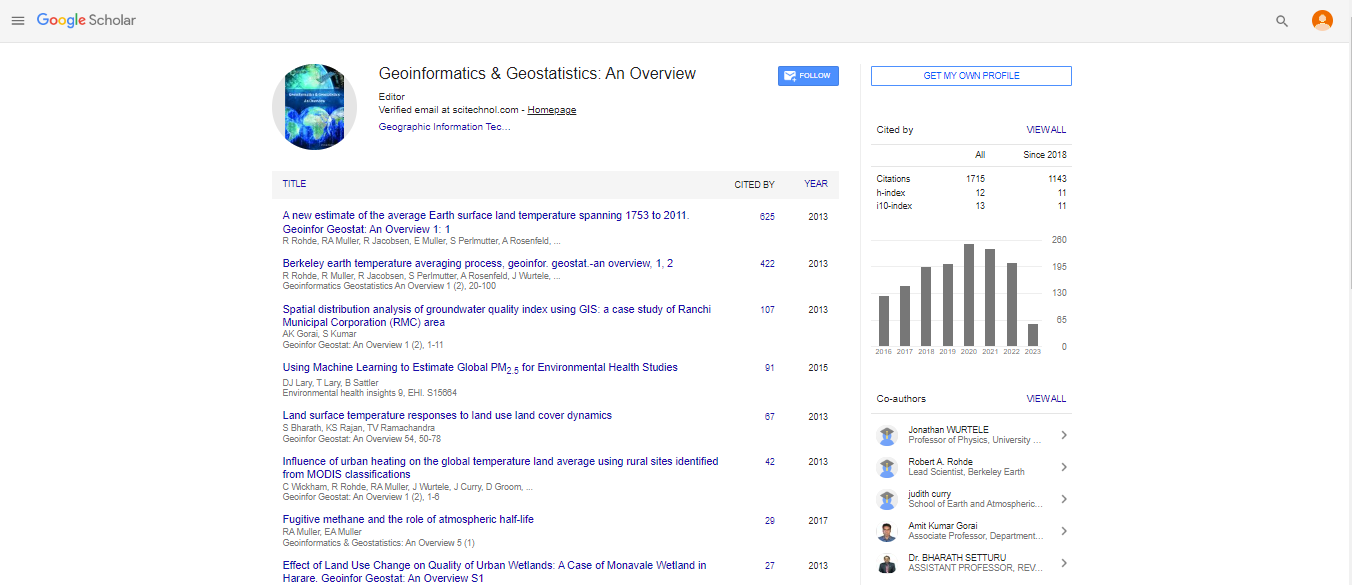
Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi Research Article, Geoinfor Geostat An Overview Vol: 3 Issue: 2
Drought Spatial Object Prediction Approach using Artificial Neural Network
| Berhan G1*, Tadesse T2 and Atnafu S3 | |
| 1Postdoctoral Researcher, School of Natural Resources, University of Nebraska-Lincoln, USA | |
| 2National Drought Mitigation Center, University of Nebraska-Lincoln, USA | |
| 3Addis Ababa University, Ethiopia | |
| Corresponding author : Berhan G Postdoctoral Researcher, School of Natural Resources, University of Nebraska-Lincoln, USA E-mail: getachewb2012@gmail.com, ttadesse2@unl.edu, solomon.atnafu@aau.edu.et |
|
| Received: October 22, 2015 Accepted: November 09, 2015 Published: November 16, 2015 | |
| Citation: Berhan G, Tadesse T, Atnafu S (2015) Drought Spatial Object Prediction Approach using Artificial Neural Network. Geoinfor Geostat: An Overview 3:2. doi:10.4172/2327-4581.1000132 |
Abstract
Drought Spatial Object Prediction Approach using Artificial Neural Network
The concept of object identification and modeling has fueled a lengthy scientific effort to convert remotely sensed images into geographic phenomena. The objective of this article was to develop a new concept for characterizing and identifying drought spatial objects from satellite images for improved drought prediction and mitigation using a back propagation artificial neural network (ANN). To characterize drought as a spatial object, 11 attributes from multi-sensors and resolutions (such as Standardized Deviation of Normalized Difference Vegetation Index [SDNDVI], Digital Elevation Model [DEM], Soil Water Holding Capacity, Ecological Regions, Land Cover, Standard Precipitation Index [SPI], and oceanic indices were used.
Keywords: Back propagation; Drought object; Modeling; Prediction; Satellite image
Keywords |
|
| Back propagation; Drought object; Modeling; Prediction; Satellite image | |
Introduction |
|
| The concept of object identification and modeling has fueled a lengthy scientific effort to convert remotely sensed images into geographic phenomena [1]. In this research, a drought spatial object is defined by the geographic phenomenon drought that is characterized by a group of pixels that can be segmented into separate regions with defined spatial locations (e.g., longitude and latitude) and attributes [2]. Object identification in remote sensing is usually done by converting raster pixel values to geographic objects. In this process, the remotely sensed image is first grouped to provide approximately homogeneous segments, and then classified into known classes [1]. According to Stein et al. [1], various procedures for image segmentation are well documented and include procedures based on mathematical morphology, edge detection, and identification of homogeneity in one band or in a set of bands. Classification routines include statistical routines such as k-nearest neighbor classifiers and increasingly fuzzy classification methods. | |
| The main objective of several remote sensing studies is to identify objects that have an ontological representation on the earth’s surface. These objects can have different meanings, and they can be of various types and shapes. A segmentation procedure is commonly first applied to identify homogeneous sets of pixel values in one or more bands [1]. | |
| The concept of identifying and modeling drought as an object is new [3]. Rulinda et al. [3] indicated that “a next step in drought modeling is an approach focusing on spatial object and this kind of object can be built from different temporal and spatial resolution images.” In remote sensing, objects are identified and subsequently classified on the basis of pixel information, and the objects are then tracked over time, during which their behavior may be governed by external factors that also have to be identified and quantified [1]. | |
| In remotely sensed images, a pixel or group of pixels with similar spectral reflectance are used to characterize the objects of interest. Remote-sensing object-classification methods usually consider information regarding the texture of features on the earth. The pixels identified as having the same texture are grouped, and the groups are considered as objects [2]. These objects can represent physical features on earth, such as roads, parcels, or water bodies. When these physical features are classified based on texture, they are considered to be physical objects [2]. Expanding upon this basic concept, this research identifies virtual objects by using incidence of vegetation stress during drought to identify virtual drought spatial objects (using drought classes of extreme drought, severe drought, moderate drought, near-normal, and above optimum) on the real ground. To characterize the virtual drought object, 11 attributes from multisensors and resolutions were used. The objective of this article was to develop a new concept for characterizing and identifying drought spatial objects from satellite images for improved drought prediction and mitigation using a back propagation artificial neural network (ANN). Materials and methods are presented in detail in section 2. Section 3 discusses the experimental analysis using artificial neural networks, and section 4 presents the conclusions and future research recommendations. | |
Materials and Methods |
|
| The identification of a drought object from a group of pixels involved a number of scientific investigations, including the identification of the key attributes characterizing drought, modeling drought using these key attributes, and evaluating the reliability of the models. Eleven attributes characterizing drought were iteratively selected for this research. | |
| Attribute selection | |
| In the attribute selection process, we used Akaike’s Information Criterion (AIC) [4-6], Variance Inflation Factor (VIF) [6-8], and Moran’s I index [6,9]. The AIC was used as a model performance by including a given potential attribute; the VIF was used as a parameter for controlling the duplication of the information of the potential attribute with previously selected attributes; and Moran’s I index was used as a parameter for controlling absence of key attributes and for avoiding misspecification of the drought spatial object model. The three parameters used for selecting the relevant attributes in the whole experimental process are presented in Figure 1 for the subsequent modeling experiment. In this figure, floristic region (flor_Rgion) is not connected with the relevance metrics, since this attribute was not related to the dependent attribute. Using these criteria, 11 attributes were identified for modeling drought spatial objects. The lists, acronyms, format, sources and references of these attributes are presented in Table 1 [10-22]. | |
| Figure 1: Diagrammatic illustration of the iterative process for selecting relevant attributes. | |
| Table 1: Attributes identified for drought spatial object modeling experiment. | |
| Data source | |
| The data used for this study were obtained from biophysical and remote sensing imagery sources (Table 1) within the extent of Ethiopia (East Africa). Ethiopia occupies the interior of the Greater Horn of Africa, stretching between 3° and 14° N latitude and 33° and 48° E longitude (Figure 2), with a total area of 1.13 million km2 [23]. Figure 2 presents the grid point extraction locations within the spatial extent of Ethiopia. For each grid point, all input data variables were extracted to be used in developing a prediction model. | |
| Figure 2: Map showing the distributions of the 2812 grid points in Ethiopia. | |
| ANN training and prediction experiment | |
| In the ANN modeling, the network was used for predicting oneto four-month SDNDVI values (agricultural drought) using the 11 key attributes of drought. As a typical neural network model [24], the network in the drought model had three types of processing units. The first units were the 11 input drought attributes. The second units were functions characterizing drought severity extent and the third units were the hidden units (the weights characterizing the drought attributes and the output drought severity extent). | |
| The weights associated with these connections (w) constitute what a neural net knows and determine the output from an arbitrary input from the environment [24,25]. Using this principle, a back propagation network with an appropriate weight (w) was used to model the relationships between the key attributes and the target drought value. In this process, the network learning algorithm searched through the space of w for a set of weights offering the best fit with the training sample data. | |
| From the available learning algorithms in ANN, a back propagation algorithm is an effective learning technique that is capable of exploiting regularities and exceptions in training sample data [25]. This algorithm was also used for drought forecasting [26] in the past, and interesting results were obtained. For these reasons, a back propagation algorithm was used in drought exploratory analysis and prediction experiments. | |
| To get the appropriate ANN models, four steps were followed: assembling the data for the actual training, creating the network object, training the network, and simulating response to new inputs (model testing). For training and testing, 67,488 records from the 24 years (1983-2006) of historical data were used. Of these, 80% were used for training and 20% for testing the models. The data split, 80-20% (80% for training and 20% for testing), was based on similar research, where improved results were found for a 80-20% split compared to other splits, such as 50-50%, 60-40%, and 70-30% [27]. The training and test datasets were randomly selected using the RANDBETWEEN function in Microsoft Excel. After generating the random number, sorting was done to split the training and test datasets. The Neural Network Toolbox on Matlab v7.9.0 [28] was used to build the ANN models. | |
| A supervised training (training with the guidance of an expert) method was used in this study. The reason for using supervised training instead of unsupervised training was that during the experimental training, the expected outputs were already known (the drought object). In this kind of scenario (when expected outputs are known), both MathWorks [28] and Heaton [29] recommend supervised training as the appropriate training method. The workflow in the drought training experiment is presented in Figure 3. In this training process, the neural network adjusts the values in the weight matrix based on the differences between the anticipated output and the actual output. A sample of the learning curve, with a learning rate of 0.04, is presented in Figure 4. | |
| Figure 3: Workflow in supervised drought object training. | |
| Figure 4: PANN learning curve on training data. | |
| In the training mode of ANN, the algorithm requires a certain number of hidden layers and neurons in the hidden layer. The number of layers was decided based on the recommendation of Heaton [29]. Heaton [29] recommended that two hidden layers be used when the objective of the analysis is to approximate smooth mapping to a reasonable accuracy level of the output. After reviewing other similar studies [30,31], we used two hidden layers in our analysis (Figure 5). In this study, 20 neurons were used for each hidden layer, and the network was trained for 500 epochs (a completed iteration of the training procedure) using a back propagation algorithm with a learning rate of 0.04. Investigating the influence of a different number of neurons and epochs on drought prediction is beyond the scope of the current research. | |
| Figure 5: A screenshot from ANN back propagation training. | |
Experimental Analysis and Discussions |
|
| Drought object model attributes selection | |
| To select the key attributes, all attributes that were identified from past research were statistically explored for their relationships with the new drought object model developed in this study. Since 11 explanatory attributes were identified, it was not possible to present all the statistical explanatory analysis in this subsection. For this reason, four key attributes were selected and the steps followed for all key attributes are presented using these sample attributes. These four attributes were also assumed to be the most significant and also the most repeatedly used by past research [32-34]. The selected attributes were DEM, WHC, 3-month SPI and SDNDVI. For the attribute DEM alone, the r-squared was 0.095, AIC was 8,012.92 and spatial autocorrelation (Global Moran’s I index) was 0.58 (p<0.01). The interpretation for this is that DEM alone can explain about 10% of the variability of drought. The spatial autocorrelation also showed that there is statistically significant clustering of the ordinary least squares (OLS) residuals in this prediction process. The null hypothesis is that there is clustering of the residuals, and this hypothesis cannot be rejected. This means that all the key attributes that explain SDNDVI are not included in the model. This is a logically meaningful statistical output in that only DEM is included from the other potential attributes collected from previous research. Each of these attributes was tested using the same procedure as the DEM attribute. | |
| In an iterative way, different combinations of the explanatory variables were tested. Some of the iterative combinations are presented in Table 2. In all of the combinations, the expected signs of the coefficients have been checked. All of the explanatory variables were found to have coefficient values as expected. For instance, as the 3-month SPI values decrease, the SDNDVI values have to decrease; conversely, as the 3-month SPI values increase, the SDNDVI values have to increase. This is because both values are showing the drought and non-drought situation of a given location as confirmed by past research [32-34]. Therefore, these attributes can be reliably used for representing a drought object. | |
| Table 2: Experimental result of key attribute selection for modeling drought objects. | |
| The r-squared values were used as a model fitness criterion (Table 2). From the various combinations, the r-squared ranged from 0.11 to 0.85. This means that these models can explain from 11% to 85% of the drought object variability. It was also realized that as the number of attributes increases, the r-squared was found to increase. The highest R2 (i.e., 0.85) was found when the August SDNDVI was included in the various combinations. The August SDNDVI alone can also explain about 82% of the variability of the September SDNDVI. This is expected because the NDVI value of the previous month (August) is correlated with the following predicted month (September). The Akaike’s Information Criterion (AIC) ranges from 6,797 to 8,017. The AIC model selection criterion is based on the fact that no single model represents the whole truth or complete information about the phenomenon under investigation, and models only approximate reality [4]. Based on this principle, Akaike [5] developed a relative index for a model that would best approximate reality using some set of explanatory variables. Since it is a relative value (the smaller the value, the better the model) for comparing models [5,35], the AIC in this research was used to compare the models for relatively better representation of the drought object. Interestingly, the lowest AIC value was obtained when the four attributes were combined for modeling the drought object (Table 2). This indicates the strong relationships of the explanatory variables with the dependent variable. As the number of explanatory variables increases, drought variability is captured in the model. | |
| The statistical analysis output of the model from the four explanatory attributes (DEM, WHC, August 3-month SPI, SDNDVI August) is presented in Table 3. As can be observed, all the coefficients are statistically significant. The Variance Inflation Factor (VIF) value, which is a measure of the severity of multicollinearity in regression analysis [7], was also found to be low in all the attributes. Multicollinearity here is the statistical phenomenon in which two or more predictor variables in the regression model are highly correlated [7,8]. Obrien [8] indicated that a VIF value greater than 10 usually shows the existence of multicollinearity. As a guide, ESRI [6] recommended that the VIF value should be less than 7.5 for GIS data. The maximum VIF value recorded in the drought object model using the four attributes is 1.89, which is much less than the recommended value (Table 3). Therefore, using the four key attributes, drought in September is: | |
| Table 3: Exploratory data analysis output of drought object model. | |
| DroughtObject = 10.62 – 0.0098DEM + 0.96 SDNDVI August + 0.1179 WHC + 0.122 August 3-month SPI. | |
| Cross-validation of drought ANN models | |
| To cross-validate the drought object models, the data were randomly split into two sets: a training dataset (80%) and a test dataset (20%). Accordingly, 53,990 records were used for training and 13,498 records for testing. | |
| The learned parameters from the data in the training dataset were subjected to those parameters in the test dataset. The prediction qualities of the models were then evaluated by comparing the predictions with the target data (SDNDVI). Using the 24 years of data, the one- to four-month drought prediction models’ performance on test datasets for the growing months (June to October) are presented in Figure 6 (a–j) using regression scatter plots (i.e., observed versus predicted) and the best-fit line. | |
| Figure 6: Scatter plots of observed and predicted drought object using ANN: The red lines are the best fits for the scatter plots. | |
| As can be observed from Figure 6, the best fit for the June prediction model was obtained for the one-month prediction (r-squared=0.72). Both July one-month and two-month predictions (for August and September) showed best fit (i.e., r-squared=0.84 and 0.69, respectively) as expected. The August one-month prediction (for September) was also found to be the best fit (rsquared=0.90) as compared to the two-month prediction (r-squared=0.53). The September one month prediction model also has a low correlation value (r-squared = 0.59) as compared to the other growing months (i.e., June, July, and August) one-month prediction models. September one-month prediction (predicting October using September data) was low because September is in the growing period whereas October is dry and vegetation in the study area is partially or fully senesced. In all the predictions for October, the scatter plot has extreme outlier values, and it needs further investigation. At each iteration, the correlation coefficient (r) (which is a measure of the accuracy levels of the models) was assessed. The summary of these accuracy levels for different time-lag predictions is presented in Table 4. The highest correlation coefficient was for Augusts’ one-month prediction (predicting September using August data). This is in agreement with our expectations. Both these months are vigorous plant-growing periods and can be captured by NDVI data, and the two datasets are the same. The lowest correlation was for June’s three-month prediction (using June data to predict September). This is also in line with our expectations: June is drier and it marks the start of the growing season, while September is within the vigorous plant growth period. | |
| Table 4: Prediction accuracy of the networks on the test dataset. | |
Conclusions |
|
| In this research, we developed a scientific approach for modeling and predicting drought as a spatial object. To characterize and identify drought spatial objects, relevant attributes were selected using AIC, VIF and Moran’s I index. | |
| The AIC (a relative value to compare between models) was used as a model performance by including a given potential attribute and was found to have a value range of 6,797.2-8,016.5. The lowest AIC value was obtained when the four attributes were combined for modeling drought objects, which is in agreement with our expectations and established theoretical framework. The VIF as a parameter for controlling the duplication of the information of the potential attribute with previously selected attributes was found to have a maximum value of 1.89, which is much lower than the recommended 7.5. The Moran’s I index as a parameter for controlling absence of key attributes and for avoiding misspecification of the drought spatial object model was assessed by checking the clustering of the residuals, and in all of the assessed models there was no clustering of the residuals. This iterative way of attribute selection is helpful in developing reliable ANN models for predicting drought in one- to four-month time lags. | |
| The output of this new concept could help in integrating the available information from multisensors and resolutions for droughtmitigation applications at different levels of decision making. Future research may focus on experimenting with the approach in wider coverage areas, such as regional or continental levels, and quantifying the uncertainty level of the approach for its practical use in drought adaptation planning and mitigation applications. Future research may also focus on identifying optimum neuron numbers in ANN, specifically in optimizing too few and too many neurons in the hidden layers for improved drought object prediction. | |
Acknowledgments |
|
| This work was supported by NASA Project NNX14AD30G and IT Doctoral Program of Addis Ababa University, Ethiopia (http://www.aau.edu.et/itphd/). We also thank Deborah Wood of the National Drought Mitigation Center for her editorial comments. | |
References |
|
|
|